Puertos Primarios vs Secundarios en Hexagonal: La Confusión Fundamental que Comete Casi Todo el Mundo
Una guía exhaustiva sobre la verdadera diferencia entre puertos primarios y secundarios en arquitectura hexagonal, por qué casi todos lo entienden mal, y cómo implementarlos correctamente en Go. Con ejemplos, diagramas y patrones verificables.
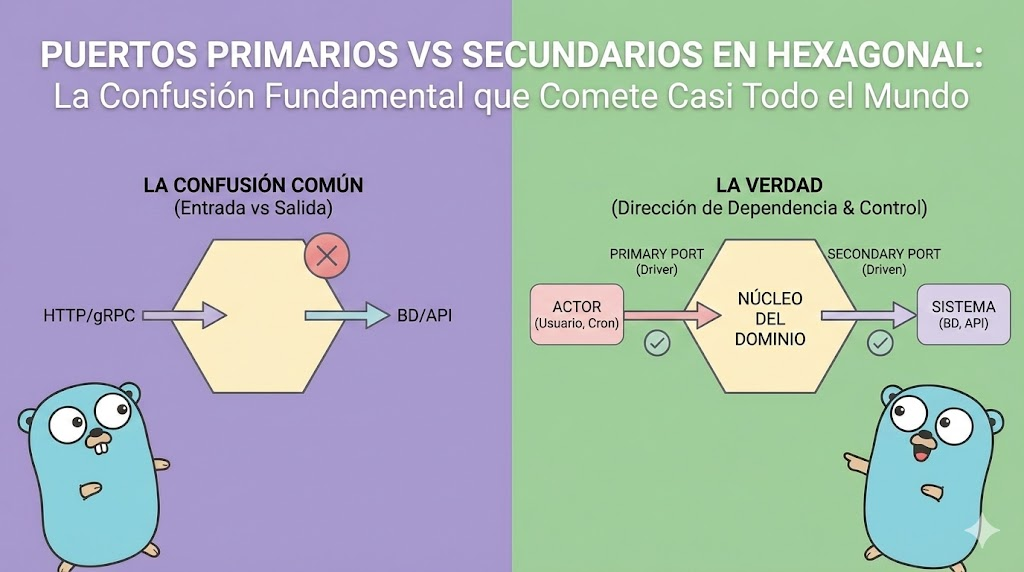
Existe una confusión tan profunda y tan generalizada sobre puertos primarios y secundarios en arquitectura hexagonal que incluso equipos que creen tener hexagonal “correcto” están equivocados.
La confusión típica que escucho:
“Los puertos primarios son las entradas (HTTP, gRPC), y los puertos secundarios son las salidas (BD, APIs externas).”
Suena razonable. Es consistente. Y está casi completamente equivocado.
La verdad es mucho más profunda: la diferencia entre puertos primarios y secundarios no es sobre “entrada vs salida”. Es sobre la dirección de la dependencia y el control del flujo. Y entender esta diferencia es la clave para construir una arquitectura hexagonal que realmente funcione.
He visto equipos que creyeron tener puertos primarios y secundarios correctamente implementados, solo para descubrir meses después que su arquitectura estaba completamente rota. Los puertos primarios y secundarios estaban mezclados. Las dependencias apuntaban en direcciones incorrectas. El “cambio fácil” que hexagonal promete resultó siendo imposible.
Este artículo es una exploración exhaustiva de la verdadera naturaleza de los puertos primarios y secundarios. Explicaré qué son realmente, cuál es la confusión común, cómo Go hace que sea especialmente fácil confundirse, y cómo implementarlos correctamente. Con ejemplos claros, diagramas arquitectónicos, y patrones que puedes aplicar ahora mismo en tu codebase.
Parte 1: Definiciones Superficiales vs Realidad
1.1 Lo Que Crees Que Sabes
Si alguien te pregunta “¿Cuál es la diferencia entre puertos primarios y secundarios?”, probablemente responderías:
Puertos Primarios: Son la “entrada” al sistema. APIs HTTP, gRPC, CLI. Puertos Secundarios: Son la “salida”. Bases de datos, APIs externas, caching.
Esta definición es lo suficientemente intuitiva para parecer verdadera. Y por eso es peligrosa. Porque es incompleta.
1.2 La Realidad: Dirección de Dependencia
En realidad, la diferencia está en esto:
Puerto Primario: Un endpoint que el mundo externo activa. El mundo controla cuándo y cómo se llama.
Puerto Secundario: Un servicio que tu dominio requiere y controla. Tu dominio decide cuándo y cómo usarlo.
¿Es la diferencia clara? No realmente. Necesitamos un ejemplo concreto.
1.3 Ejemplo Que Lo Clarifica
Imagina un servicio de procesamiento de órdenes:
Escenario A: HTTP (Puerto Primario)
Cliente HTTP
↓ (GET /orders/123)
Servidor HTTP (adapter primario)
↓
Handler HTTP
↓
Caso de Uso: GetOrderUseCase
↓
Dominio: OrderFlujo de control: Cliente controla cuándo se ejecuta. El cliente dice “GET /orders/123” y el servidor responde. El flujo viene de afuera hacia adentro.
Escenario B: Base de Datos (Puerto Secundario)
Dominio: Order
↓ (necesito datos persistidos)
Caso de Uso: GetOrderUseCase
↓
Puerto: OrderRepository
↓
Adapter: PostgresOrderRepository
↓
Base de DatosFlujo de control: El caso de uso controla cuándo se ejecuta. El caso de uso dice “necesito la orden con ID 123” y llama al repositorio. El flujo viene de adentro hacia afuera.
Esta es la diferencia fundamental.
1.4 Dirección de Dependencia
Si dibujamos las dependencias:
Puerto Primario:
┌─────────────────────────────────┐
│ Mundo Externo (HTTP) │ ← Es quien llama
├─────────────────────────────────┤
│ Adapter Primario (Handler) │ ← Escucha y traduce
├─────────────────────────────────┤
│ Dominio (Use Case) │ ← Es quien responde
└─────────────────────────────────┘
Dependencia: Cliente → Handler → UseCasePuerto Secundario:
┌─────────────────────────────────┐
│ Dominio (Use Case) │ ← Es quien inicia
├─────────────────────────────────┤
│ Puerto (Interface) │ ← Define contrato
├─────────────────────────────────┤
│ Adapter Secundario (Postgres) │ ← Implementa contrato
├─────────────────────────────────┤
│ Mundo Externo (BD) │ ← Es quien responde
└─────────────────────────────────┘
Dependencia: UseCase → Interface → Adapter → DatabaseLa clave: En puertos primarios, el adaptador NO es una interfaz (el cliente puede ser cualquier cosa). En puertos secundarios, el adaptador implementa una interfaz que el dominio controla.
Parte 2: La Confusión Común y Sus Consecuencias
2.1 La Confusión Típica #1: “Todo Es Entrada O Salida”
La confusión más común es ver puertos primarios vs secundarios como simplemente:
- Primario = request que llega
- Secundario = dato que sale
Pero esto rompe cuando preguntas: “¿Qué pasa con webhooks? ¿Qué pasa con eventos asíncronos? ¿Qué pasa con un servicio que consume una API externa?“
2.2 Escenario de Desastre: Webhook (Puerto Primario O Secundario?)
Imagina que necesitas integrar con un servicio externo que te envía webhooks cuando algo cambia:
Servicio Externo
↓ (POST /webhooks/payment-received)
Tu Servidor
↓
Handler¿Es esto un puerto primario o secundario?
- Respuesta equivocada: “Es un puerto primario porque es una entrada HTTP”
- Respuesta correcta: “Es un puerto primario porque el mundo externo activa el flujo. El webhook viene de afuera, nosotros no lo controlamos”
¿Y si el webhook es de un servicio que TÚ requieres?
No cambia la respuesta. Sigue siendo primario.
2.3 Escenario de Desastre: API Externa (¿Puerto Secundario?)
Ahora imagina que TÚ necesitas consultar una API externa:
Tu Código
↓ (GET https://api.external.com/data/123)
API Externa
↓
Respuesta¿Es esto un puerto secundario?
- Respuesta equivocada: “Sí, porque es una salida”
- Respuesta correcta: “Sí, es un puerto secundario porque tu dominio controla cuándo se llama. Tu código decide: necesito datos de la API, voy a llamarla”
2.4 El Patrón Incorrecto Que Surge
Cuando confundes esto, terminas con un patrón peligroso:
// ❌ MALO: Mezclando primario con secundario
type OrderUseCase struct {
// Puerto primario: Alguien externos hace HTTP
httpHandler *HTTPHandler
// Puerto secundario: Requiero persistencia
repo OrderRepository
}
func (o *OrderUseCase) GetOrder(id string) (*Order, error) {
order, err := o.repo.GetByID(id)
if err != nil {
return nil, err
}
// Ahora el uso case actúa como si fuera un cliente HTTP
// Esto está completamente mal
o.httpHandler.SendResponse(order)
return order, nil
}El problema: El caso de uso no debería saber sobre handlers HTTP. El handler HTTP debería saber sobre el caso de uso, no al revés.
Parte 3: La Verdadera Definición, Explicada
3.1 Puerto Primario: “El Mundo Externo Me Controla”
Un puerto primario es un punto donde el mundo externo inicia una acción que tu dominio responde.
Características:
- El mundo externo decide cuándo activarlo (no tu código)
- El mundo externo envía datos de entrada
- Tu código genera una respuesta
- El mundo externo consume la respuesta
Ejemplos de puertos primarios:
├── HTTP REST API
│ GET /users/123 → Handler → UseCase → Domain → Response
├── gRPC Server
│ rpc GetUser(request) → Handler → UseCase → Domain → Response
├── Webhooks (Incoming)
│ POST /webhooks/payment → Handler → UseCase → Domain → Response
├── CLI
│ $ myapp get-user 123 → Handler → UseCase → Domain → Response
├── AMQP Consumer
│ message received → Handler → UseCase → Domain → processed
└── Message Queue Listener
event received → Handler → UseCase → Domain → responseEl patrón:
┌────────────────────────────────────┐
│ Mundo Externo (Cliente, Usuario) │
└────────────────────────────────────┘
↓ Inicia
┌────────────────────────────────────┐
│ Adapter Primario (Handler, Router) │
└────────────────────────────────────┘
↓ Traduce
┌────────────────────────────────────┐
│ UseCase / Application Service │
└────────────────────────────────────┘
↓ Orquesta
┌────────────────────────────────────┐
│ Domain (Entities, Business Logic) │
└────────────────────────────────────┘3.2 Puerto Secundario: “Mi Dominio Me Controla”
Un puerto secundario es un punto donde tu dominio inicia una acción que el mundo externo responde.
Características:
- Tu código decide cuándo activarlo
- Tu código envía datos
- El mundo externo genera una respuesta
- Tu código consume la respuesta
Ejemplos de puertos secundarios:
├── Persistencia
│ UseCase → Repository Interface → PostgreSQL/MongoDB
├── APIs Externas
│ UseCase → PaymentGateway Interface → Stripe/Paypal
├── Caching
│ UseCase → Cache Interface → Redis/Memcached
├── Búsqueda
│ UseCase → SearchEngine Interface → Elasticsearch/Algolia
├── Envío de Email
│ UseCase → EmailService Interface → SendGrid/SMTP
└── Logging/Analytics
UseCase → Logger Interface → CloudWatch/DatadogEl patrón:
┌────────────────────────────────────┐
│ Domain (Entities, Business Logic) │
└────────────────────────────────────┘
↓ Requiere
┌────────────────────────────────────┐
│ Puerto Secundario (Interface) │
└────────────────────────────────────┘
↓ Implementado por
┌────────────────────────────────────┐
│ Adapter Secundario (Postgres, API) │
└────────────────────────────────────┘
↓ Conecta a
┌────────────────────────────────────┐
│ Mundo Externo (Database, Service) │
└────────────────────────────────────┘3.3 La Diferencia Visual
Puerto Primario = Adaptador Pasivo
Cliente HTTP
↓
Handler HTTP (escucha, espera)
↓
UseCase (responde)
↓
Response
El handler NO inicia. Escucha y responde.Puerto Secundario = Adaptador Activo
UseCase (iniciador)
↓
Repository (interfaz: contrato)
↓
PostgresRepository (implementación)
↓
Database (responde)
El adapter actúa en respuesta al UseCase.Parte 4: Cómo Go Hace Que Sea Fácil Confundirse
4.1 La Trampa: Interfaces Everywhere
En Go, es fácil crear interfaces sin pensar. Y esto hace que sea especialmente fácil mezclar puertos primarios y secundarios.
// ❌ Confuso: ¿Es esto primario o secundario?
type Handler interface {
Handle(ctx context.Context, req interface{}) (interface{}, error)
}
// ¿Es un handler primario (HTTP)?
// ¿Es un handler de dominio?
// ¿Es ambos?4.2 El Patrón Peligroso: Adaptadores Bifacéticos
He visto código como este:
// ❌ MALO: Un adapter que actúa como primario Y secundario
type UserController struct {
repo *PostgresUserRepository // Secundario
http *HTTPHandler // Primario?
}
func (u *UserController) CreateUser(w http.ResponseWriter, r *http.Request) {
// Esto es un handler primario
user := parseRequest(r)
// Pero también actúa como secundario
if err := u.repo.Save(user); err != nil {
return
}
// Y aquí vuelve a actuar como primario
u.http.WriteJSON(w, user)
}Los problemas:
- El controller mezcla responsabilidades
- No está claro qué es primario y qué es secundario
- Si necesitas cambiar la persistencia, afecta el handler
- Si necesitas agregar otro adapter primario (gRPC), tienes que refactorizar
4.3 Por Qué Ocurre: Simplicidad Aparente
Go permite esto porque la distinción entre primario y secundario no está forzada por el lenguaje. En Go, todo es solo una interfaz.
Esto es libertad, pero también es una trampa.
Parte 5: La Implementación Correcta
5.1 Patrón: Separación Clara de Responsabilidades
Paso 1: Definir puertos secundarios en el dominio
// 📁 internal/domain/port.go
// Estos puertos viven en el dominio porque el dominio los requiere
// Puerto Secundario: Persistencia
type UserRepository interface {
GetByID(ctx context.Context, id string) (*User, error)
Save(ctx context.Context, user *User) error
Delete(ctx context.Context, id string) error
}
// Puerto Secundario: Notificación
type EmailNotifier interface {
Send(ctx context.Context, to string, subject string, body string) error
}
// Puerto Secundario: Logging
type Logger interface {
Info(msg string)
Error(msg string, err error)
}Paso 2: Definir casos de uso que usan los puertos
// 📁 internal/usecase/create_user.go
// El caso de uso REQUIERE los puertos secundarios
type CreateUserUseCase struct {
repo UserRepository
emailNotifier EmailNotifier
logger Logger
}
func (c *CreateUserUseCase) Execute(ctx context.Context, email, password string) (*User, error) {
// Lógica de dominio
user := &User{
Email: email,
PasswordHash: hashPassword(password),
}
// Usa puertos secundarios (el dominio decide cuándo)
if err := c.repo.Save(ctx, user); err != nil {
c.logger.Error("Failed to save user", err)
return nil, err
}
if err := c.emailNotifier.Send(ctx, email, "Welcome", "Welcome to our service"); err != nil {
c.logger.Error("Failed to send email", err)
// ¿Rollback? ¿Reintentar? Decisión de negocio
}
c.logger.Info("User created: " + email)
return user, nil
}Paso 3: Crear adapters secundarios
// 📁 internal/adapter/repository/postgres_user.go
// Implementa el puerto que el dominio define
type PostgresUserRepository struct {
db *sql.DB
}
func (p *PostgresUserRepository) GetByID(ctx context.Context, id string) (*User, error) {
row := p.db.QueryRowContext(ctx, "SELECT * FROM users WHERE id = $1", id)
var user User
if err := row.Scan(&user.ID, &user.Email); err != nil {
return nil, err
}
return &user, nil
}
func (p *PostgresUserRepository) Save(ctx context.Context, user *User) error {
_, err := p.db.ExecContext(ctx,
"INSERT INTO users (id, email, password_hash) VALUES ($1, $2, $3)",
user.ID, user.Email, user.PasswordHash)
return err
}
// ... más métodosPaso 4: Crear adapters primarios
// 📁 internal/adapter/http/user_handler.go
// El handler es el adapter primario
// Escucha requests HTTP y los traduce a casos de uso
type UserHandler struct {
createUserUseCase *CreateUserUseCase
getUserUseCase *GetUserUseCase
}
func (h *UserHandler) CreateUser(w http.ResponseWriter, r *http.Request) {
// Parse request (primario → secundario)
var req CreateUserRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, "Invalid request", http.StatusBadRequest)
return
}
// Llama al caso de uso (el cliente HTTP inició esto)
user, err := h.createUserUseCase.Execute(r.Context(), req.Email, req.Password)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// Write response (secundario → primario)
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
json.NewEncoder(w).Encode(user)
}
func (h *UserHandler) GetUser(w http.ResponseWriter, r *http.Request) {
id := r.PathValue("id")
user, err := h.getUserUseCase.Execute(r.Context(), id)
if err != nil {
http.Error(w, "Not found", http.StatusNotFound)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(user)
}Paso 5: Composición en main
// 📁 cmd/api/main.go
// Aquí es donde conectas todo
func main() {
db := setupDatabase()
// Adapters secundarios
userRepo := &PostgresUserRepository{db: db}
emailNotifier := &SendGridEmailNotifier{apiKey: os.Getenv("SENDGRID_KEY")}
logger := &ZeroLogger{}
// Casos de uso
createUserUseCase := &CreateUserUseCase{
repo: userRepo,
emailNotifier: emailNotifier,
logger: logger,
}
// Adapter primario
handler := &UserHandler{
createUserUseCase: createUserUseCase,
}
// Rutas
mux := http.NewServeMux()
mux.HandleFunc("POST /users", handler.CreateUser)
http.ListenAndServe(":8080", mux)
}5.2 Diagrama Completo
┌─────────────────────────────────────────────────┐
│ MUNDO EXTERNO │
├─────────────────────────────────────────────────┤
│ HTTP Client | Database | Email Service │
└─────────────────────────────────────────────────┘
↓ ↑
│ inicia │ responde
↓ ↑
┌─────────────────────────────────────────────────┐
│ PUERTOS PRIMARIOS (ADAPTERS PRIMARIOS) │
│ ├── HTTPHandler (escucha POST /users) │
│ ├── gRPCServer (escucha rpc calls) │
│ └── CLIHandler (escucha comandos) │
└─────────────────────────────────────────────────┘
↓ traduce ↑ responde
│ │
↓ ↑
┌─────────────────────────────────────────────────┐
│ CASOS DE USO (APPLICATION SERVICES) │
│ ├── CreateUserUseCase │
│ ├── GetUserUseCase │
│ └── DeleteUserUseCase │
└─────────────────────────────────────────────────┘
│ requiere ↑
↓ │ responde
┌─────────────────────────────────────────────────┐
│ PUERTOS SECUNDARIOS (INTERFACES DE DOMINIO) │
│ ├── UserRepository (persistencia) │
│ ├── EmailNotifier (notificaciones) │
│ └── Logger (logging) │
└─────────────────────────────────────────────────┘
↓ implementado por ↑ implementa
│ │
↓ ↑
┌─────────────────────────────────────────────────┐
│ ADAPTERS SECUNDARIOS (IMPLEMENTACIONES) │
│ ├── PostgresUserRepository │
│ ├── SendGridEmailNotifier │
│ └── ZeroLogger │
└─────────────────────────────────────────────────┘5.3 Flujo de Control: Quién Llama a Quién
PUERTO PRIMARIO (HTTP):
┌────────────────────┐
│ Cliente HTTP │ ← Inicia
└────────────────────┘
↓
┌────────────────────┐
│ HTTPHandler │ ← Escucha y traduce
└────────────────────┘
↓
┌────────────────────┐
│ CreateUserUseCase │ ← Ejecuta lógica
└────────────────────┘
↓
┌────────────────────┐
│ UserRepository │ ← Requiere (llama)
└────────────────────┘
↓
┌────────────────────┐
│ PostgresRepository │ ← Ejecuta
└────────────────────┘
↓
┌────────────────────┐
│ Database │ ← Responde
└────────────────────┘
Resumen: Cliente → Handler → UseCase → [UseCase → Repo → DB]
Nota: El UseCase CONTROLA cuándo se llama a Repository.
El Cliente NO CONTROLA cuándo se ejecuta, pero el Handler sí lo escucha.Parte 6: Casos Especiales y Confusión Extra
6.1 ¿Qué Pasa Con Los Eventos?
Los eventos son un caso especial que causa mucha confusión.
Patrón Event Sourcing (Puerto Secundario):
// Puerto Secundario: Almacenamiento de eventos
type EventStore interface {
Append(ctx context.Context, event DomainEvent) error
GetByAggregateID(ctx context.Context, id string) ([]DomainEvent, error)
}
// El UseCase requiere el EventStore
type CreateOrderUseCase struct {
eventStore EventStore
}
func (c *CreateOrderUseCase) Execute(ctx context.Context, order *Order) error {
// Crea un evento
event := OrderCreatedEvent{OrderID: order.ID}
// Lo persiste (el UseCase controla cuándo)
return c.eventStore.Append(ctx, event)
}Es un puerto secundario porque el UseCase controla cuándo se llama.
6.2 ¿Qué Pasa Con Los Webhooks Que Envío?
Si TÚ necesitas enviar webhooks a clientes externos, eso es un puerto secundario:
// Puerto Secundario: Webhook delivery
type WebhookSender interface {
Send(ctx context.Context, url string, payload interface{}) error
}
type OrderService struct {
repo OrderRepository
webhookSender WebhookSender
}
func (o *OrderService) CreateOrder(ctx context.Context, order *Order) error {
// Persiste
if err := o.repo.Save(ctx, order); err != nil {
return err
}
// Envía webhook (el UseCase controla cuándo)
return o.webhookSender.Send(ctx, "https://client.com/webhook", order)
}Es secundario porque TU CÓDIGO controla cuándo enviar.
6.3 ¿Qué Pasa Con Los Webhooks Que Recibo?
Si un cliente externo te envía webhooks, eso es un puerto primario:
// Puerto Primario: Webhook receiver
func (h *WebhookHandler) StripeWebhook(w http.ResponseWriter, r *http.Request) {
// El webhook fue enviado por Stripe (externo controla)
var event stripe.Event
json.NewDecoder(r.Body).Decode(&event)
// Traduce a caso de uso
err := h.processPaymentUseCase.Execute(r.Context(), event)
if err != nil {
http.Error(w, "Error", http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusOK)
}Es primario porque EL MUNDO EXTERNO controla cuándo sucede.
Parte 7: Checklist - ¿Lo Estás Haciendo Bien?
7.1 Para Puertos Primarios
Para cada adapter primario, verifica:
- ¿El adapter primario ESCUCHA un evento externo? (HTTP request, CLI command, webhook)
- ¿Traduce la entrada externa a un caso de uso?
- ¿El caso de uso NO SABE que existe este adapter primario?
- ¿Puedo cambiar de HTTP a gRPC sin modificar el caso de uso?
- ¿El adapter primario SOLO orquesta entre entrada externa y caso de uso?
- ¿No toma decisiones de negocio?
- ¿Es “thin” (delgado)?
Si contestas “no” a cualquiera, tienes un problema.
7.2 Para Puertos Secundarios
Para cada puerto secundario, verifica:
- ¿El puerto está DEFINIDO en el dominio (o como máximo en application)?
- ¿El caso de uso REQUIERE este puerto?
- ¿El caso de uso DECIDE cuándo llamarlo?
- ¿Hay al menos una implementación (adapter)?
- ¿Hay una implementación “fake” para testing?
- ¿Si cambio la implementación, el caso de uso no cambia?
- ¿La interfaz describe QUÉ hace, no CÓMO?
- ¿Puedo crear un mock fácilmente para testing?
Si contestas “no” a cualquiera, tienes un acoplamiento.
7.3 Checklist de Arquitectura Completa
Verificaciones generales:
- ¿Las dependencias apuntan siempre hacia el dominio?
- ¿Los adapters primarios no conocen adapters secundarios?
- ¿El dominio no importa
adapter/? - ¿Los casos de uso SOLO dependen de puertos (interfaces)?
- ¿Tengo implementaciones fake para cada puerto?
- ¿Puedo cambiar de una tecnología a otra sin tocar dominio?
- ¿Los adapters primarios son “thin”?
- ¿Los adapters secundarios son “thin”?
Parte 8: Ejemplos Comparativos
8.1 Ejemplo Completo: E-Commerce
❌ MALO: Puertos confundidos
// Todo mezclado
type ProductService struct {
httpHandler *HTTPHandler // Primario
db *sql.DB // Secundario directo
stripe *stripe.Client // Secundario directo
emailService *mail.SMTP // Secundario directo
}
func (p *ProductService) BuyProduct(w http.ResponseWriter, productID string) error {
// Es un handler HTTP (primario)
product, err := p.db.Query("SELECT * FROM products WHERE id = ?", productID)
if err != nil {
return err
}
// Pero también accede directamente a la BD
err = p.stripe.Charge(product.Price)
if err != nil {
return err
}
// Y a Stripe directamente
p.emailService.Send("Compra confirmada")
// Y a Email directamente
w.WriteJSON(product)
// Y escribe la respuesta HTTP
return nil
}Problemas:
- Todo mezclado en una sola función
- No hay separación de responsabilidades
- El primario depende del secundario
- No puedes testear sin todas las dependencias
✅ BIEN: Puertos separados
// 📁 internal/domain/port.go
type ProductRepository interface {
GetByID(ctx context.Context, id string) (*Product, error)
}
type PaymentGateway interface {
Charge(ctx context.Context, amount float64) error
}
type EmailService interface {
SendConfirmation(ctx context.Context, email string, product *Product) error
}
// 📁 internal/usecase/buy_product.go
type BuyProductUseCase struct {
repo ProductRepository
payment PaymentGateway
email EmailService
}
func (b *BuyProductUseCase) Execute(ctx context.Context, productID string) (*Product, error) {
// Solo lógica de dominio
product, err := b.repo.GetByID(ctx, productID)
if err != nil {
return nil, err
}
if err := b.payment.Charge(ctx, product.Price); err != nil {
return nil, err
}
if err := b.email.SendConfirmation(ctx, "user@example.com", product); err != nil {
// Logging, pero no falla toda la operación
}
return product, nil
}
// 📁 internal/adapter/http/product_handler.go
type ProductHandler struct {
buyProductUseCase *BuyProductUseCase
}
func (h *ProductHandler) Buy(w http.ResponseWriter, r *http.Request) {
// Solo maneja HTTP
productID := r.PathValue("id")
product, err := h.buyProductUseCase.Execute(r.Context(), productID)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(product)
}
// 📁 internal/adapter/repository/postgres_product.go
type PostgresProductRepository struct {
db *sql.DB
}
func (p *PostgresProductRepository) GetByID(ctx context.Context, id string) (*Product, error) {
row := p.db.QueryRowContext(ctx, "SELECT * FROM products WHERE id = $1", id)
var product Product
if err := row.Scan(&product.ID, &product.Name, &product.Price); err != nil {
return nil, err
}
return &product, nil
}
// Similar para StripePaymentGateway, SendGridEmailService...Ventajas:
- Cada capa tiene responsabilidad clara
- Puedo testear sin BD, sin Stripe, sin Email
- Puedo cambiar implementaciones fácilmente
- Puedo agregar otro adapter primario (gRPC) fácilmente
Parte 9: Los Errores Más Comunes
9.1 Error #1: Adapter Primario Que Llama Directamente a Adapters Secundarios
// ❌ MALO
type UserHandler struct {
db *sql.DB // No debería estar aquí
stripe *stripe.Client // No debería estar aquí
}
func (h *UserHandler) CreateUser(w http.ResponseWriter, r *http.Request) {
// El handler no debería saber de DB o Stripe
user := parseRequest(r)
h.db.Exec("INSERT INTO users...") // ❌ Directo a BD
h.stripe.CreateCustomer(...) // ❌ Directo a Stripe
}
// ✅ BIEN
type UserHandler struct {
createUserUseCase *CreateUserUseCase // Depende de caso de uso
}
func (h *UserHandler) CreateUser(w http.ResponseWriter, r *http.Request) {
user := parseRequest(r)
// Solo orquesta
result, err := h.createUserUseCase.Execute(r.Context(), user)
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(result)
}9.2 Error #2: Caso de Uso Que Toma Decisiones de Primario
// ❌ MALO
type CreateUserUseCase struct {
repo UserRepository
}
func (c *CreateUserUseCase) Execute(w http.ResponseWriter, r *http.Request) error {
// El UseCase NO debería saber de HTTP
user := parseFromHTTP(r)
if err := c.repo.Save(user); err != nil {
http.Error(w, "Error", 500) // ❌ El UseCase escribe HTTP
return err
}
w.WriteJSON(user) // ❌ El UseCase escribe respuesta
return nil
}
// ✅ BIEN
func (c *CreateUserUseCase) Execute(ctx context.Context, email, password string) (*User, error) {
// El UseCase es agnóstico a HTTP
// Solo devuelve datos
user := &User{Email: email, PasswordHash: hash(password)}
if err := c.repo.Save(ctx, user); err != nil {
return nil, err
}
return user, nil
}9.3 Error #3: Múltiples Adapters Primarios Duplicando Lógica
// ❌ MALO
type HTTPHandler struct {
repo UserRepository
}
type gRPCHandler struct {
repo UserRepository // Misma lógica, duplicada
}
func (h *HTTPHandler) GetUser(...) { h.repo.GetByID(...) }
func (g *gRPCHandler) GetUser(...) { g.repo.GetByID(...) }
// ✅ BIEN
type GetUserUseCase struct {
repo UserRepository
}
type HTTPHandler struct {
getUser *GetUserUseCase // Reutiliza
}
type gRPCHandler struct {
getUser *GetUserUseCase // Reutiliza
}
func (h *HTTPHandler) GetUser(...) { h.getUser.Execute(...) }
func (g *gRPCHandler) GetUser(...) { g.getUser.Execute(...) }Conclusión: La Distinción que Importa
Puertos primarios vs secundarios no es sobre “entrada vs salida”.
Es sobre quién controla el flujo:
- Primario: El mundo externo inicia, mi código responde
- Secundario: Mi código inicia, el mundo externo responde
Esta distinción cambia completamente cómo estructuras tu código, cómo lo testeas, y cómo puedes evolucionarlo sin romper la arquitectura.
La mayoría de equipos entienden esto superficialmente. Solo cuando lo implementan correctamente, descubren el verdadero poder de la arquitectura hexagonal: la capacidad de cambiar una tecnología completamente sin tocar tu dominio.
Es esta distinción clara entre primario y secundario lo que hace esto posible.
Artículos relacionados
Por relevancia
Interfaces Implícitas vs Explícitas en Go: Cómo la Magia se Convierte en Pesadilla
Una guía profunda sobre las interfaces implícitas en Go, por qué es peligroso en arquitectura hexagonal, cómo Go te permite escribir 'hexagonal sin pensarlo', y por qué eso rompe la arquitectura. Con ejemplos de desastre real y patrones para hacerlo bien.
Interfaces en Go: La verdadera magia que cambia cómo programas
Una guía exhaustiva sobre interfaces en Go: qué son, cómo funcionan, cómo se crean, satisfacción implícita, composición, casos reales, y por qué Go rompe el paradigma de otros lenguajes. Desde novatos hasta expertos.

El Mito del 'Cambio Fácil': Por Qué Hacer que Sea Fácil Cambiar Postgres por MySQL No Es Un Beneficio Real
Una exploración profunda del mito arquitectónico más peligroso: la idea de que hacer 'fácil cambiar de base de datos' es un beneficio real. Analizamos por qué casi nunca sucede, cuál es el verdadero costo, y cuándo realmente tiene sentido.
Nil en Go: Por Qué Es Peligroso y Cómo Manejarlo (Verdaderamente)
Una exploración exhaustiva sobre nil en Go: qué es, por qué causa tantos bugs, cómo afecta arquitectura, patrones para evitarlo, y cómo diseñar APIs que minimicen nil errors. Con 40+ ejemplos de código y anti-patrones reales.