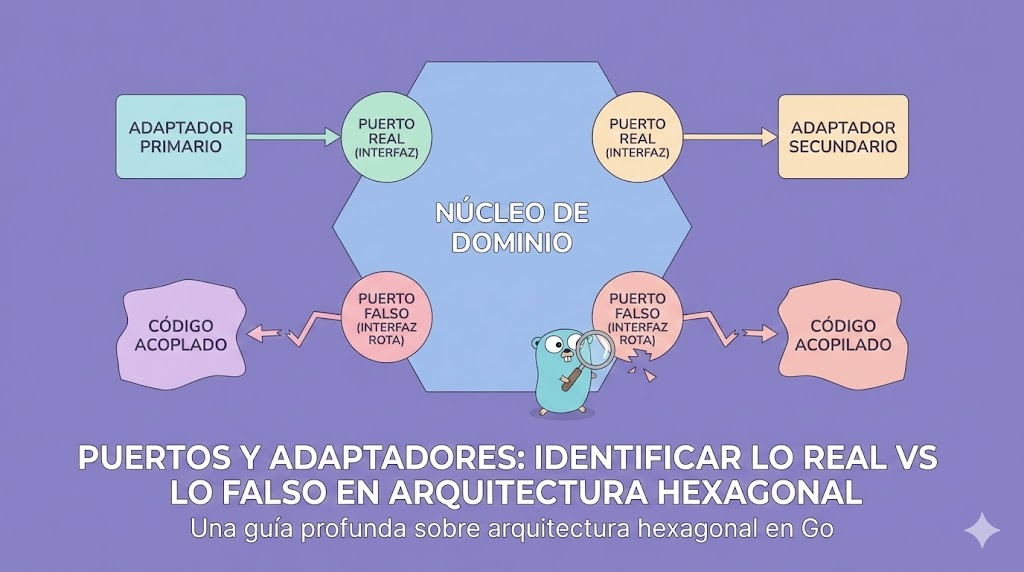
Puertos y Adaptadores: Identificar lo Real vs Lo Falso en Arquitectura Hexagonal
Una guía profunda sobre arquitectura hexagonal en Go: qué son realmente los puertos, cómo identificarlos correctamente, diferencia entre adapters primarios y secundarios, errores comunes que rompen la arquitectura, y patrones verificables en código.
Existe un misterio en la arquitectura de software que confunde incluso a desarrolladores experimentados: la diferencia entre entender la arquitectura hexagonal y hacerla bien.
Puedo mostrar a diez equipos diferentes la misma lección sobre puertos y adaptadores. Nueve de ellos creerán que lo entienden. Seis meses después, cuando necesitan refactorizar o escalar, descubrirán que sus “puertos” no son puertos en absoluto. Son solo interfaces aleatorias. Su arquitectura no fue hexagonal, solo parecía serlo.
La verdad incómoda: identificar puertos reales es una habilidad que se aprende, no algo obvio leyendo teoría. La diferencia entre un puerto legítimo y una interfaz que parece un puerto es sutil pero fundamental. Y la diferencia entre adapters primarios y secundarios no es lo que la mayoría cree.
Este artículo es una inmersión profunda en la verdadera naturaleza de los puertos y adaptadores. No es introducción. Es desmenuzar lo que está mal en casi toda implementación de hexagonal que veo, explicar por qué, y mostrarte cómo hacerlo bien. Con código real, decisiones arquitectónicas explicadas, y patrones que puedes aplicar inmediatamente.
Parte 1: La Ilusión de Entender Hexagonal
1.1 Lo Que Crees Que Entiendes
Si alguien te preguntara ahora mismo: “¿Qué es un puerto en arquitectura hexagonal?”, probablemente responderías algo como:
“Un puerto es una interfaz que define cómo el dominio se comunica con el mundo exterior.”
Suena bien. Es técnicamente correcto en teoría. Pero si miras el código de 100 proyectos que creen tener “hexagonal architecture”, encontrarás que 80 de ellos entienden los puertos de forma superficial.
La pregunta de verdad es: ¿cuál interfaz en mi aplicación es un puerto, y cuál es solo “una interfaz porque Go tiene interfaces”?
1.2 El Experimento Mental: Cuatro Interfaces
Imagina que tienes estas cuatro interfaces en tu codebase:
// Interfaz 1
type UserRepository interface {
GetByID(id string) (*User, error)
Save(user *User) error
}
// Interfaz 2
type Logger interface {
Info(msg string)
Error(msg string, err error)
}
// Interfaz 3
type Clock interface {
Now() time.Time
}
// Interfaz 4
type Serializer interface {
Marshal(v interface{}) ([]byte, error)
Unmarshal(data []byte, v interface{}) error
}Pregunta: ¿Cuáles son puertos reales y cuáles son solo interfaces?
La mayoría de desarrolladores dirían:
- ✅
UserRepositoryes un puerto (accede a datos) - ✅
Loggeres un puerto (sale del sistema) - ✅
Clockes un puerto (consulta hora externa) - ❌
Serializerno es un puerto (es utilidad)
Y sí, la mayoría tiene razón. Pero la razón por la que está correcta no es la que creen.
1.3 Por Qué Casi Todos Lo Hacen Mal
El error fundamental es confundir “necesitamos una interfaz” con “esto es un puerto”.
Un puerto no es simplemente “una interfaz que permite swap de implementaciones”. Un puerto es algo más específico:
Un puerto es un límite arquitectónico donde tu dominio se comunica con el mundo exterior, y donde ese mundo exterior podría cambiar sin afectar la lógica de negocio.
Déjame repetir eso porque es la clave:
Un puerto existe en un límite arquitectónico donde lo que está afuera podría cambiar completamente sin afectar lo que está adentro.
Viéndolo de esta forma:
- UserRepository: Sí es un puerto. Podrías cambiar de MongoDB a PostgreSQL sin tocar el dominio. ✅
- Logger: Sí es un puerto. Podrías cambiar de
logrusazapsin tocar el dominio. ✅ - Clock: Sí es un puerto. Podrías usar reloj del sistema o un reloj simulado para tests. ✅
- Serializer: NO es un puerto. Serializar JSON es parte de cómo comunicas datos al mundo. Si cambias el formato de serialización, ya no es la misma API. ❌
Pero aquí viene la parte que nadie enseña: la diferencia es mucho más sutil cuando estás construyendo tu aplicación.
Parte 2: Cómo Identificar Puertos Reales
2.1 El Criterio de los Tres Cambios
Existe un test mental simple para saber si algo es un puerto:
Pregúntate: “Si cambiara X, ¿tendría que cambiar mi código de dominio?”
Si la respuesta es “sí”, probablemente no es un puerto. Es lógica de negocio que simplemente vive en el adaptador.
Ejemplo 1: UserRepository
// Dominio
type User struct {
ID string
Email string
Name string
}
// Puerto
type UserRepository interface {
GetByID(id string) (*User, error)
Save(user *User) error
}Pregunta: Si cambio la implementación de UserRepository de MongoDB a PostgreSQL, ¿cambia mi código de dominio?
Respuesta: No. El dominio sigue siendo exactamente igual. Solo la implementación del puerto cambia.
Conclusión: Esto es un puerto legítimo. ✅
Ejemplo 2: EmailSender (Trampa)
type EmailSender interface {
Send(to, subject, body string) error
}Pregunta: Si cambio de SendGrid a Mailgun, ¿cambia mi código de dominio?
Parece que no, ¿verdad? Pero espera…
¿Qué pasa si SendGrid permite HTML pero Mailgun no? ¿Qué pasa si uno requiere from y otro no? ¿Qué pasa si uno tiene límite de 50 destinatarios por batch y otro no?
La realidad: el adaptador de email necesita validaciones que el dominio no sabe que existen.
Entonces la pregunta real es: ¿está mi dominio acoplado a las características específicas de este proveedor de email?
Si respondiste “sí”, entonces no es un puerto puro. Es un adaptador que filtra acceso a un puerto.
2.2 El Patrón de los Límites Claros
Los puertos reales tienen una característica: existe una línea clara donde el sistema entra o sale del dominio.
Dibujemos esto:
┌─────────────────────────────────────────┐
│ DOMINIO (Lógica de Negocio) │
│ - User, Form, Rules, Validations │
│ │
│ ▲ (Entrada) ▼ (Salida) │
│ ╭──┴──┬────────────┬──┴──╮ │
└──┤ Puerto Entrada │ Puerto Salida ├──┘
│ (HTTP) │ (BD, Queue) │
│ │ │
▼ ▼ ▲
┌──────────┐ ┌────────┐ ┌──────────┐
│ HTTP │ │MongoDB │ │ Logger │
│ Handler │ │ │ │ │
└──────────┘ └────────┘ └──────────┘Nota que el dominio está en el centro, sin saber que existen HTTP, MongoDB o Logger. Los puertos son contratos que dice:
- Puerto de entrada (HTTP): “Yo tomo requests HTTP y los convierto en operaciones de dominio”
- Puerto de salida (BD): “Yo tomo operaciones de dominio y las persisto en BD”
- Puerto de salida (Logger): “Yo tomo eventos de dominio y los logueo”
Característica clave: El dominio nunca importa los paquetes de los adaptadores.
// ✅ CORRECTO: Dominio no conoce adaptadores
package domain
import (
"fmt"
)
type User struct { ... }
func (u *User) ChangeEmail(newEmail string) error {
// No importa HTTP, BD, Logger, nada
// Solo lógica de negocio
}
// ❌ INCORRECTO: Dominio acoplado a adaptadores
package domain
import (
"fmt"
"github.com/lib/pq" // ← ¡DAO está filtrando!
)
type User struct { ... }2.3 La Pregunta del Reemplazo
Existe un test que casi nunca falla:
Pregunta: “Si tuviera que reemplazar este adaptador en producción SIN cambiar NADA en el dominio, ¿podría hacerlo?”
Ejemplo 1: UserRepository de MongoDB a PostgreSQL
Pasos necesarios:
- Escribir nueva implementación de
UserRepositorypara PostgreSQL - Cambiar la inyección de dependencias
- Nada más cambia
Respuesta: Sí, es un puerto. ✅
Ejemplo 2: Logger de logrus a zap
Pasos necesarios:
- Escribir nueva implementación de
Logger - Cambiar la inyección de dependencias
- Nada más cambia
Respuesta: Sí, es un puerto. ✅
Ejemplo 3: Password Hashing de Bcrypt a Argon2
Pasos necesarios:
- Escribir nueva implementación de
PasswordHasher - Cambiar la inyección
- ¿Nada más?
Aquí viene lo importante: si tu dominio tiene lógica que depende de características de Bcrypt (salt rounds, timing, etc), entonces PasswordHasher no es un puerto puro. Es un filtro.
Parte 3: Adapters Primarios vs Secundarios (Lo Que Nadie Entiende)
3.1 La Definición Correcta (No La Que Ves En Google)
Casi todo lo que lees sobre “adapters primarios vs secundarios” es incorrecto o confuso. La mayoría dice algo como:
“Adapters primarios: llevan requests del usuario (HTTP). Adapters secundarios: acceden a recursos externos (BD).”
Es técnicamente correcto en algunos casos, pero conceptualmente impreciso. La verdadera diferencia es:
Adapters primarios: El mundo exterior inicia comunicación. El adaptador convierte esa comunicación en llamadas al dominio.
Adapters secundarios: El dominio inicia comunicación. El adaptador convierte esas llamadas en acciones del mundo exterior.
3.2 Direcciones de Flujo
┌────────────────────────────────────────┐
│ DOMINIO │
└────────────────────────────────────────┘
▲ ▼
│ │
┌────┴───┐ ┌──────┴─┐
│ PRIMARY│ │SECONDARY│
│ADAPTER │ │ADAPTER │
└────────┘ └─────────┘
▲ ▼
HTTP Request Database Write
(External) (External)
iniciates is initiated by
the flow the domainEjemplo 1: HTTP Handler (Primary)
// Adaptador Primario: HTTP
func HandleCreateUser(w http.ResponseWriter, r *http.Request) {
// El MUNDO EXTERNO (cliente HTTP) inicia este flujo
// 1. Parsear request
var createReq CreateUserRequest
json.NewDecoder(r.Body).Decode(&createReq)
// 2. Llamar al dominio
user, err := useCase.CreateUser(createReq.Email, createReq.Name)
// 3. Convertir respuesta de dominio a HTTP
json.NewEncoder(w).Encode(user)
}Flujo: Cliente HTTP → Adaptador → Dominio
Ejemplo 2: Database Repository (Secondary)
// Adaptador Secundario: Base de Datos
func (r *PostgresUserRepository) Save(user *User) error {
// El DOMINIO inicia este flujo
// El adaptador está aquí para servir al dominio
// Convertir entidad de dominio a estructura de BD
dbUser := &DBUser{
ID: user.ID,
Email: user.Email,
}
// Persistir
_, err := r.db.Exec("INSERT INTO users ...", dbUser)
// El dominio no sabe que esto sucedió
return err
}Flujo: Dominio → Adaptador → Base de datos
3.3 Por Qué Importa La Diferencia
Adapters Primarios:
- Son “controladores” del sistema
- El dominio no los conoce
- Pueden cambiar sin afectar dominio
- Pero son necesarios para que el dominio haga algo
Adapters Secundarios:
- Son “repositorios” del sistema
- El dominio depende de sus interfaces (puertos)
- Deben poder ser reemplazados sin tocar dominio
- Son donde vive la complejidad técnica
3.4 Múltiples Adapters Primarios (La Confusión Usual)
Una aplicación típica tiene:
Adapters Primarios:
├── HTTP REST API
├── gRPC Server
├── CLI Tool
└── Message Queue Consumer
↓ (todos envían al mismo dominio)
DOMINIO
↑ (todos usan los mismos puertos)
Adapters Secundarios:
├── PostgreSQL Repository
├── Redis Cache
├── Email Service
└── LoggerTodos los adapters primarios diferentes comparten el mismo dominio y los mismos adapters secundarios.
¿Por qué? Porque el negocio es el mismo: tus reglas, tu lógica, tu esencia.
Solo cambia cómo esa lógica se comunica con el mundo.
Parte 4: Errores Comunes Que Rompen la Arquitectura
4.1 Error #1: “Mi Handler Es Mi Caso de Uso”
// ❌ INCORRECTO
func HandleCreateUser(w http.ResponseWriter, r *http.Request) {
// Lógica de validación de negocio
var req CreateUserRequest
if req.Email == "" {
http.Error(w, "Email required", 400)
return
}
// Acceso a BD directamente
user := &User{ID: uuid.New().String(), Email: req.Email}
db.Save(user)
// Response
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(user)
}Problema: La lógica de negocio vive en el adaptador HTTP. Si quieres usar tu dominio desde gRPC, CLI, o mensaje queue, tienes que replicar toda esa lógica.
// ✅ CORRECTO
// Adaptador HTTP (primario)
func HandleCreateUser(w http.ResponseWriter, r *http.Request) {
var req CreateUserRequest
json.NewDecoder(r.Body).Decode(&req)
user, err := createUserUseCase.Execute(req.Email, req.Name)
if err != nil {
// Convertir errores de dominio a HTTP
w.WriteHeader(http.StatusBadRequest)
json.NewEncoder(w).Encode(ErrorResponse{Message: err.Error()})
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(user)
}
// Caso de Uso (dominio)
type CreateUserUseCase struct {
repo UserRepository // Puerto secundario
}
func (uc *CreateUserUseCase) Execute(email, name string) (*User, error) {
if email == "" {
return nil, errors.New("email required")
}
user := User{ID: uuid.New().String(), Email: email, Name: name}
if err := uc.repo.Save(&user); err != nil {
return nil, err
}
return &user, nil
}Diferencia clave: La lógica está en el caso de uso, no en el handler.
4.2 Error #2: “Tengo Muchos Puertos, Debo Estar Haciendo Bien”
// ❌ Demasiados puertos falsos
type CreateUserUseCase struct {
userRepo UserRepository // ← Puerto legítimo
logger Logger // ← Puerto legítimo
emailValidator EmailValidator // ← NO es puerto (es lógica de negocio)
passwordHasher PasswordHasher // ← Discutible
uuidGenerator UUIDGenerator // ← NO es puerto
clock Clock // ← Puerto legítimo
metricsCollector MetricsCollector // ← NO es puerto
configProvider ConfigProvider // ← NO es puerto
}Problema: No todo que se inyecta es un puerto. Algunos de estos son:
- Utilidades que deberían estar en el dominio
- Adaptadores para herramientas técnicas, no de negocio
- Detalles de implementación que no deberían ser configurables
// ✅ Puertos claros
type CreateUserUseCase struct {
userRepo UserRepository // DB: podría cambiar
logger Logger // Logging: podría cambiar
clock Clock // Tiempo: podría cambiar (importante para tests)
}
func (uc *CreateUserUseCase) Execute(email, name string) (*User, error) {
// Validación de email vive AQUÍ, en el dominio
if !isValidEmail(email) {
return nil, errors.New("invalid email")
}
// Hashear contraseña vive AQUÍ
hashedPassword := hashPassword(password)
// Solo los VERDADEROS puertos se inyectan
user := &User{
ID: uuid.New().String(),
Email: email,
Password: hashedPassword,
CreatedAt: uc.clock.Now(),
}
if err := uc.userRepo.Save(user); err != nil {
uc.logger.Error("failed to save user", err)
return nil, err
}
return user, nil
}
// Funciones de utilidad (lógica de negocio, no puertos)
func isValidEmail(email string) bool {
return strings.Contains(email, "@")
}
func hashPassword(password string) string {
// Bcrypt es un detalle técnico, no un puerto
hashed, _ := bcrypt.GenerateFromPassword([]byte(password), 10)
return string(hashed)
}4.3 Error #3: “Confundir Adapters Primarios con el Dominio”
// ❌ INCORRECTO: Confundir capas
type UserService struct {
// El servicio (dominio) no debería conocer que existe HTTP
w http.ResponseWriter
r *http.Request
}// ✅ CORRECTO: Separación clara
// Adaptador Primario (HTTP)
type UserHTTPHandler struct {
createUserUseCase CreateUserUseCase
}
func (h *UserHTTPHandler) Create(w http.ResponseWriter, r *http.Request) {
// Convertir HTTP → Dominio
// Convertir Dominio → HTTP
}
// Dominio (usa casos)
type CreateUserUseCase struct {
userRepo UserRepository
}
func (uc *CreateUserUseCase) Execute(email, name string) (*User, error) {
// Sin saber que existe HTTP
}4.4 Error #4: “Los Puertos Deben Ser Generales”
// ❌ Puerto demasiado general
type DataStore interface {
Get(key string) (interface{}, error)
Set(key string, value interface{}) error
Delete(key string) error
}Este puerto es tan general que no te dice nada. ¿Es para caching? ¿Es para persistencia? ¿Qué pasa si necesitas transacciones?
// ✅ Puertos específicos al dominio
type UserRepository interface {
GetByID(id string) (*User, error)
GetByEmail(email string) (*User, error)
Save(user *User) error
Delete(id string) error
}
type FormRepository interface {
GetByID(id string) (*Form, error)
GetByCreator(userID string) ([]*Form, error)
Save(form *Form) error
}Principio: Puertos que son específicos al dominio son más útiles que puertos genéricos.
Parte 5: El Patrón Correcto Para REST + Hexagonal
5.1 Estructura de Una Petición REST Correcta
HTTP Request
↓
┌─────────────────────────────────────┐
│ Adaptador Primario (HTTP Handler) │
│ Responsabilidad: │
│ 1. Parsear request │
│ 2. Validar formato HTTP │
│ 3. Llamar caso de uso │
│ 4. Convertir respuesta a JSON │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Caso de Uso (Dominio) │
│ Responsabilidad: │
│ 1. Orquestar flujo │
│ 2. Validar reglas de negocio │
│ 3. Llamar puertos secundarios │
│ 4. Retornar resultado │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ Puertos Secundarios (Adaptadores) │
│ Responsabilidad: │
│ 1. Persistir datos │
│ 2. Acceder a recursos externos │
│ 3. Implementar detalles técnicos │
└─────────────────────────────────────┘
↓
Base de Datos / Cache / Email / etc5.2 Ejemplo Práctico: Crear Usuario
Paso 1: Definir el Puerto (Secundario)
package domain
type UserRepository interface {
GetByEmail(email string) (*User, error)
Save(user *User) error
}Nota: El puerto es propiedad del dominio, no del adaptador.
Paso 2: Definir la Entidad de Dominio
package domain
type User struct {
ID string
Email string
Name string
Password string // Hasheada
CreatedAt time.Time
}
// Lógica de negocio aquí
func NewUser(email, name, password string) (*User, error) {
if !isValidEmail(email) {
return nil, errors.New("invalid email")
}
hashedPassword := hashPassword(password)
return &User{
ID: uuid.New().String(),
Email: email,
Name: name,
Password: hashedPassword,
CreatedAt: time.Now(),
}, nil
}
func isValidEmail(email string) bool {
// Lógica de validación aquí
return strings.Contains(email, "@")
}
func hashPassword(password string) string {
hashed, _ := bcrypt.GenerateFromPassword([]byte(password), 10)
return string(hashed)
}Paso 3: Implementar el Caso de Uso
package usecase
type CreateUserUseCase struct {
userRepo domain.UserRepository
}
type CreateUserInput struct {
Email string
Name string
Password string
}
func (uc *CreateUserUseCase) Execute(input CreateUserInput) (*domain.User, error) {
// Verificar que el usuario no existe
existing, _ := uc.userRepo.GetByEmail(input.Email)
if existing != nil {
return nil, errors.New("user already exists")
}
// Crear usuario (lógica de dominio)
user, err := domain.NewUser(input.Email, input.Name, input.Password)
if err != nil {
return nil, err
}
// Persistir
if err := uc.userRepo.Save(user); err != nil {
return nil, err
}
return user, nil
}Paso 4: Implementar el Adaptador Secundario
package adapter
type PostgresUserRepository struct {
db *sql.DB
}
func (r *PostgresUserRepository) GetByEmail(email string) (*domain.User, error) {
var user domain.User
err := r.db.QueryRow(
"SELECT id, email, name, password, created_at FROM users WHERE email = $1",
email,
).Scan(&user.ID, &user.Email, &user.Name, &user.Password, &user.CreatedAt)
if err == sql.ErrNoRows {
return nil, nil
}
if err != nil {
return nil, err
}
return &user, nil
}
func (r *PostgresUserRepository) Save(user *domain.User) error {
_, err := r.db.Exec(
"INSERT INTO users (id, email, name, password, created_at) VALUES ($1, $2, $3, $4, $5)",
user.ID, user.Email, user.Name, user.Password, user.CreatedAt,
)
return err
}Paso 5: Implementar el Adaptador Primario (HTTP)
package adapter
type CreateUserRequest struct {
Email string `json:"email"`
Name string `json:"name"`
Password string `json:"password"`
}
type CreateUserResponse struct {
ID string `json:"id"`
Email string `json:"email"`
Name string `json:"name"`
CreatedAt time.Time `json:"created_at"`
}
type UserHTTPHandler struct {
createUserUseCase *usecase.CreateUserUseCase
}
func (h *UserHTTPHandler) Create(w http.ResponseWriter, r *http.Request) {
// 1. Parsear request
var req CreateUserRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, "invalid request", http.StatusBadRequest)
return
}
// 2. Llamar caso de uso
user, err := h.createUserUseCase.Execute(usecase.CreateUserInput{
Email: req.Email,
Name: req.Name,
Password: req.Password,
})
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
// 3. Convertir respuesta
resp := CreateUserResponse{
ID: user.ID,
Email: user.Email,
Name: user.Name,
CreatedAt: user.CreatedAt,
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
json.NewEncoder(w).Encode(resp)
}Paso 6: Prueba Esta Arquitectura
Nota qué puedes hacer ahora:
// Prueba unitaria del caso de uso (sin BD real)
func TestCreateUser(t *testing.T) {
mockRepo := &MockUserRepository{}
useCase := &CreateUserUseCase{userRepo: mockRepo}
user, err := useCase.Execute(CreateUserInput{
Email: "test@example.com",
Name: "Test",
Password: "secret",
})
assert.NoError(t, err)
assert.NotNil(t, user)
}
// Prueba de integración HTTP (con BD real)
func TestHTTPCreateUser(t *testing.T) {
repo := NewPostgresUserRepository(db)
useCase := NewCreateUserUseCase(repo)
handler := NewUserHTTPHandler(useCase)
req := httptest.NewRequest("POST", "/users", strings.NewReader(`{"email":"test@example.com","name":"Test","password":"secret"}`))
w := httptest.NewRecorder()
handler.Create(w, req)
assert.Equal(t, http.StatusCreated, w.Code)
}¿Ves el poder? Cada capa tiene una responsabilidad clara. El dominio no sabe de HTTP. Los tests son rápidos. Los adapters son intercambiables.
Parte 6: Diferencias Sutiles Que Importan
6.1 Puertos vs Configuración
// ❌ ¿Es esto un puerto?
type ConfigProvider interface {
Get(key string) string
}No. Configuración no es un puerto. Es un detalle de inicialización.
// ✅ Esto es un puerto
type Logger interface {
Info(msg string)
Error(msg string, err error)
}Sí. Logger es un puerto porque el dominio puede tener diferentes implementaciones.
Diferencia: Configuración es “cómo configuramos el sistema”. Puertos son “cómo el sistema interactúa con el mundo”.
6.2 Transversales vs Puertos
// ❌ Esto NO es un puerto (es transversal)
type MetricsCollector interface {
Record(metric string, value float64)
}Métricas son transversales. Afectan toda la aplicación pero no son puertos.
Mejor enfoque:
// Emitir eventos del dominio
type DomainEventBus interface {
Publish(event DomainEvent)
}
// Los adaptadores secundarios se suscriben a estos eventos
type MetricsAdapter struct {
eventBus DomainEventBus
}6.3 Interfaces Implícitas vs Explícitas
Go soporta interfaces implícitas (la interfaz está “everywhere”) pero en hexagonal es mejor ser explícito:
// ❌ Implícito, difícil de rastrear
func NewCreateUserUseCase(repo interface{}) *CreateUserUseCase {
return &CreateUserUseCase{repo: repo}
}
// ✅ Explícito, claro
func NewCreateUserUseCase(repo domain.UserRepository) *CreateUserUseCase {
return &CreateUserUseCase{repo: repo}
}Conclusión: Cómo Saber Si Lo Estás Haciendo Bien
Verifica estos puntos:
✅ El dominio NO importa ningún paquete de adaptadores
✅ Los casos de uso orquestan el flujo, no los handlers
✅ Los puertos son específicos al dominio, no genéricos
✅ Puedes reemplazar adaptadores sin tocar el dominio
✅ Los tests del dominio no usan BD, HTTP, o servicios externos
✅ Hay claridad sobre qué es adaptador primario vs secundario
✅ La lógica de negocio está en el dominio, no en los adaptadores
Si todos estos puntos son verdad, entonces tienes hexagonal real, no solo aparente.
La diferencia está en los detalles. Y los detalles son lo que separa sistemas que escalan de sistemas que colapsan.
Artículos relacionados
Por relevancia
Gestor de Notas Seguro en Go 1.25: Arquitectura Hexagonal desde Cero
La Guía Definitiva paso a paso para construir un gestor de notas empresarial con Go 1.25, Arquitectura Hexagonal pura, JWT, roles de usuario y permisos granulares. Desde la configuración de CachyOS hasta la inyección de dependencias. Diseñado para novatos y expertos.
API Versioning Strategies: Cómo Evolucionar APIs sin Romper Clientes
Una guía exhaustiva sobre estrategias de versionado de APIs: URL versioning vs Header versioning, cómo deprecar endpoints sin shock, migration patterns reales, handling de cambios backwards-incompatibles, y decisiones arquitectónicas que importan. Con 50+ ejemplos de código en Go.
Event-Driven Architecture: Más Allá de Pub/Sub - Choreography, Orchestration y Garantías de Entrega
Una guía profunda sobre arquitectura orientada a eventos en Go: diferencia entre choreography y orchestration, cómo manejar dead letter queues, retries inteligentes, garantías de entrega en REST, y patrones verificables en producción.
Interfaces en Go: La verdadera magia que cambia cómo programas
Una guía exhaustiva sobre interfaces en Go: qué son, cómo funcionan, cómo se crean, satisfacción implícita, composición, casos reales, y por qué Go rompe el paradigma de otros lenguajes. Desde novatos hasta expertos.